
Contents
“Multiple Sclerosis Spinal Cord Lesion Detection from MultiSequence MRIs”
An uncommon but relevant task: spinal cord lesion detection
Multisequences: 4 sequences potentially available with various resolutions
Missing modalities: all four sequences not available for each patient at training and at testing
Challenge Rationale
Lesion detection: Let’s not forget the Spinal Cord
The identification of Multiple Sclerosis (MS) lesions on Magnetic Resonance Images (MRI) is a complex and mentally demanding task that often leads to an underestimation of disease activity, even for most experienced radiologists. There is thus a need for automated tools that can provide clinicians an aid for accurate and robust identification and quantification of MS lesions.
To date, the medical imaging community concentrated its efforts toward the detection/segmentation of the lesions in brain MRI. For this purpose, over the past years, several challenges have been organized to assess the ability of automated methods to detect multiple sclerosis (MS) lesions as compared to manual delineation. These have allowed the community to explore innovative directions.
However, clinically, the presence of lesions in the spinal cord has a major prognostic value compared to brain lesions. Also their detection represents a hard task for radiologists. Indeed, MS lesion detection/segmentation in spinal cord MRI is a complex task due to specific characteristics (e.g. lack of sharp contrasts between healthy and pathological tissue, high occurrence of significant artifacts). As a result, despite its clinical importance, spinal cord MRI is currently under-exploited in patients with MS. Providing clinicians with tools capable of reliably identifying these spinal cord lesions would therefore be a major added-value.
A Multisequence “Missing-Modality” Setting
Spinal cord lesion detection raises a specific methodological challenge. Indeed, in clinical practice, it is highly recommended to acquire at least two sequences among a set of available sequences, without specific guidelines to date. In practice, depending on the center and context, any combination of existing MR sequences can be provided. In this challenge, that represents a concrete complex case of multisequence datasets, we focus on four commonly used sequences: the sagittal T2 (that is always provided in the challenge and will be considered as the reference to segment), the sagittal STIR, the sagittal PSIR and the 3D MP2RAGE that will be provided in different combinations.
In practice, the training set will consist of the following pairs of acquisitions: 50 pairs of T2 and STIR data, 25 pairs of T2 and PSIR data and 25 pairs of T2 and MP2RAGE data. This data originate from various 1.5T and 3T scanners from two different brands. The testing set (not provided to challengers) will consist of the following set: 40 pairs of T2 and STIR data, 20 pairs of T2 and PSIR data, 20 pairs of T2 and MP2RAGE data and 20 triplets of T2, STIR and MP2RAGE data. Moreover, some of its data will originate from a third scanner brand.
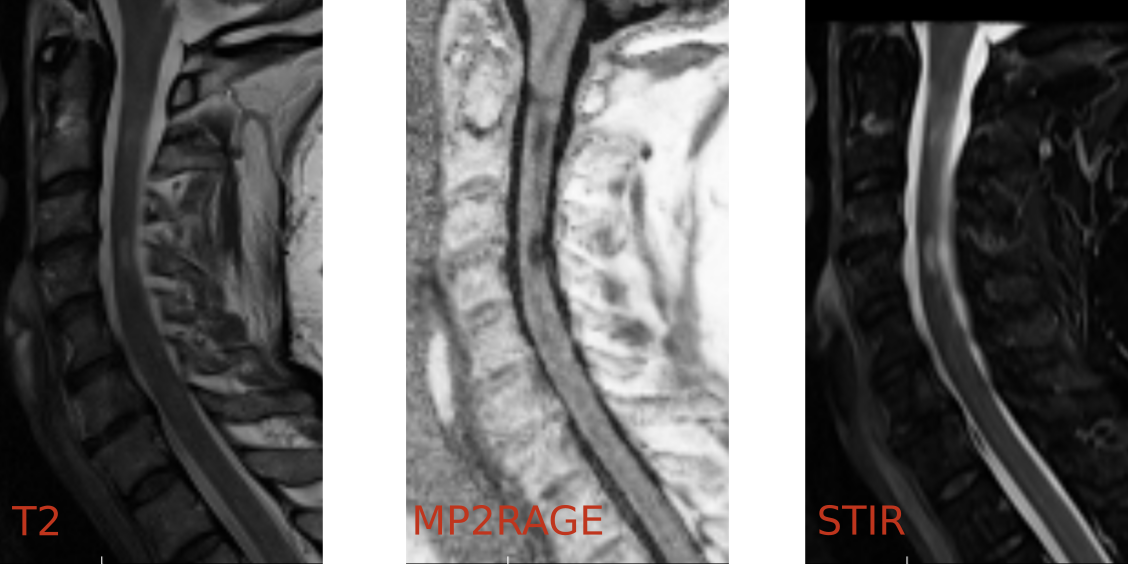
Sagittal slices from 3 sequences acquired in a given session on patient with MS
A Probabilistic Instance Segmentation Setting
Only fully automated methods will be allowed. Methodologically, the setting is those of an instance segmentation problem where probability are assigned to inferred instances and where ground-truths are provided as segmentation masks. Methods will thus be ask to output both a mask of labels (with a unique label for each voxel of a given identified lesion) and a csv file with the probabilities associated to each lesion label.
To assess the performance of lesion-wise detection of the challengers’ methods, we will use a FROC-based metrics consisting in computing the mean sensitivity averaged among the five false positive rates 0.25, 0.5, 1, 2 and 3. The achieved mean sensitivity for each of the five levels will be estimated as part of the evaluation procedure individually for each pipeline based on the probability assigned to each lesion.
The code for the evaluation is provided in Section “Resources for challengers”.
Challenge outcomes
- The challenge proceedings are available here. Each paper can be cited using:
<Authors>, <Paper Title>, In: Proceedings of the ms-multi-spine challenge on Spinal Cord Lesion Detection from MultiSequence MRIs, MICCAI-ms-multi-spine, Combès, Kerbrat, Cotton, Kain, Pop, Dojat. (Eds), pp. <pageNumbers>, 2025. - Among the methods eligible to official ranking, the one with best FROC score was “Modular Cross-Attention Fusion for Multi-Modal MS Spine Lesion Segmentation with Missing Modalities” by J. Wang, H. Liu, H. Li, F. Bagnato and I. Oguz, with a FROC=0.451. The full results are presented here. Congratulations to all the participating teams for their work!
Important Dates & Submission Process
Important dates:
- Challenge Website open: July 2, 2024
- Training data first release: December 6, 2024
December 1,2024 - Training data updated version release: March 1, 2025
- Register your intention to submit at https://ms-multispine.sciencesconf.org/: May 15, 2025
- Short paper submission deadline: June 15, 2025
- Docker submission deadline: June 15, 2025
- Announcement of the results: end of September 2025
Resources for challengers:
- Detailed Description of Data and Specification of Pipelines: available here
- Access to the Training Data Set (downloading may take some time): ask access here
- Performance Evaluation Code: available here
- Full challenge description, as submitted to Miccai: available here
- Registration website: available here
Submission process:
All details regarding the pipeline specification and its integration into the computing infrastructure are provided here. In a nutshell, here are the 4 main steps
1. Build a Docker or Singularity image containing a method compatible with the Input/Output specifications ,
2. Create a Boutiques descriptor of the tool,
3. Make the image and descriptor available to the VIP team,
4. Validate its integration with the VIP team.
Submitted pipelines will be integrated in the Virtual Imaging Platform (VIP), allowing
for their execution and evaluation on the test set (unrealeased to the challengers).
The MS-Multi-Spine Team:
Organization team:
- Romain Casey,
- Benoit Combès,
- François Cotton,
- Michel Dojat,
- Michael Kain,
- Anne Kerbrat,
- Sorina Pop.
Actively working with:
- Axel Bonnet,
- Cédric Meurée,
- Gwendal Soisnard.
For any information, please contact us at challenge-ms-multi-spine@inria.fr.
We are thankful to our institutions, partners and sponsors to have made this challenge possible.
 |
 |
 |
 |
|